Nacionālā korpusu kolekcija – ikvienam pieejami lielie valodas dati tiešsaistē

Apkopojot vairāk nekā 10 iestāžu izstrādātos latviešu valodas korpusus, izveidota Nacionālā korpusu kolekcija (NKK) ar vienotu meklēšanas sistēmu, kas pieejama platformā Korpuss.lv.
Valodas korpuss ir strukturēts rakstītu tekstu, transkribētu runas vai video ierakstu kopums, kas paredzēts lingvistiskai analīzei un valodas tehnoloģiju izstrādei. Bez šādiem jau iepriekš apkopotiem lieliem valodas resursiem mūsdienās vairs nav iedomājamas studijas un pētniecība digitālajās humanitārajās un sociālajās zinātnēs. Turklāt šādi apjomīgi un daudzveidīgi korpusi tiek izmantoti mākslīgā intelekta modeļu apmācībai. Arī pēdējos mēnešos popularitāti ieguvušais ChatGPT ir apmācīts, izmantojot ļoti lielu daudzvalodu tekstu korpusu, un ilustrē valodas korpusu lielo nozīmi – jo kvalitatīvāks korpuss, jo kvalitatīvākas virtuālā sarunu biedra atbildes.
Latviešu valodai dažādās institūcijās ir izstrādāti daudzi valodas korpusi, taču līdz šim nebija pieejama vienota korpusu platforma un meklēšanas sistēma. Šobrīd, apkopojot vairāk nekā 10 iestāžu izstrādātos latviešu valodas korpusus, izveidota Nacionālā korpusu kolekcija (NKK) ar vienotu meklēšanas sistēmu, kas pieejama platformā Korpuss.lv.
Šobrīd Korpuss.lv piedāvā meklēšanu jau 27 NKK korpusos vienlaikus. Kopējais NKK apjoms pārsniedz divus miljardus vārdu un turpina pieaugt. Šāds reprezentatīvu datu apjoms ir ļoti noderīgs ne vien lingvistiskai analīzei, bet arī valodas modelēšanai ar mašīnmācīšanos un dziļajiem neironu tīkliem.
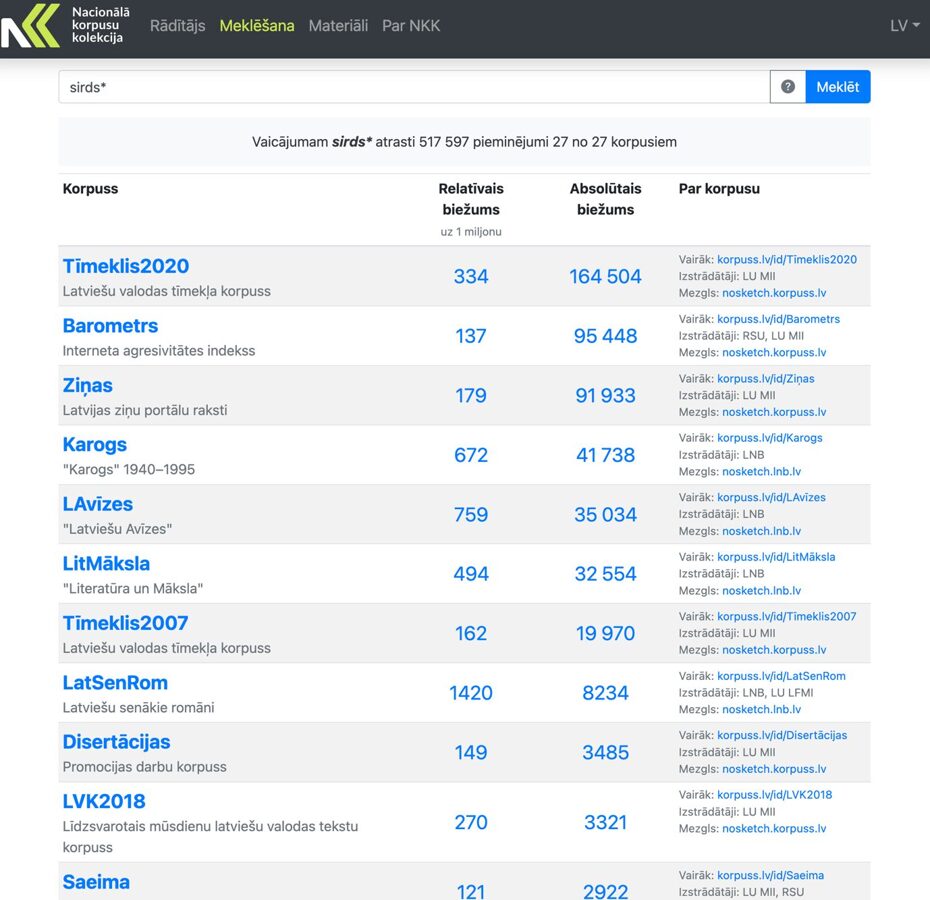
Lai lietotāji varētu efektīvi strādāt ar daudzajiem NKK korpusiem un atrastu tajos nepieciešamos valodas lietojuma piemērus, aprēķinātu to biežumu un iegūtu citu informāciju, Korpuss.lv ir izveidota decentralizēta vienotās meklēšanas sistēma. Tas ļauj vienu vaicājumu izpildīt visos NKK korpusos vienlaikus. Piemēram, vaicājumam sirds* tiek atrasti 517 597 pieminējumi 27 no 27 korpusiem – vārds sirds dažādos locījumos un atvasinājumi ar sirds- (sirdi, sirdij, sirdsapziņa, sirdslieta, sirdspuksts, sirdsmīļš, sirdsdraugs, sirdsmiers u. tml.). Atrastos vārdus, to kontekstu un avotus tālāk var aplūkot konkrētajos korpusos.
Vairums NKK korpusu ir automātiski gramatiski marķēti, izmantojot LU Matemātikas un informātikas institūta (LU MII) Mākslīgā intelekta laboratorijā izstrādāto latviešu valodas automātiskās analīzes rīkkopu LV-PIPE. Tas nozīmē, ka katram vārdam tekstā ir pievienota informācija par tā morfoloģiju, piemēram, vārdam sirdsdraudzenes tiek noteikta pamatforma un ar virkni ncfpn5 tiek norādīts, ka tas ir lietvārds (n), sugasvārds (c) sieviešu dzimtes (f) daudzskaitļa (p) nominatīvā (n) un pieder pie 5. deklinācijas (5).

Lielu daļu NKK korpusu ir izstrādājis LU MII, sadarbojoties ar citām pētniecības iestādēm un uzņēmumiem, piemēram, Rēzeknes Tehnoloģiju akadēmiju, Rīgas Stradiņa universitāti, Latvijas Universitāti, LETA un Rīgas Austrumu klīnisko universitātes slimnīcu. NKK pieejami arī LU Literatūras, folkloras un mākslas institūta un Latvijas Nacionālās bibliotēkas izveidotie korpusi.
Darbs pie NKK izveides noticis vairāku gadu garumā ar Latviešu valodas aģentūras, VPP “Humanitāro zinātņu digitālie resursi” un ERAF programmu “Praktiskas ievirzes pētījumi” atbalstu un turpinās VPP projektos “Mūsdienu latviešu valodas izpēte un valodas tehnoloģiju attīstība” un “Atvērtas un FAIR principiem atbilstīgas digitālo humanitāro zinātņu ekosistēmas attīstība Latvijā”. NKK platformas un korpusu datu ilgtermiņa uzturēšanu un starptautisku pieejamību nodrošina Eiropas vienotās valodas resursu un tehnoloģiju infrastruktūras mezgls CLARIN-LV.