Research on Modern Latvian Language and
Events
October 2024
With the support of the Latvian Council of Science, the "Easy on Science" campaign has produced several publicity materials on the project's achievements, including the video "Science Mission: Your Language":
October 15–17, 2024
Ilze Auziņa presented her paper "Language Technology Initiative - Bridging the Gap between Research and Education" (Barcelona) at the annual CLARIN conference.
October 4–5, 2024
Milan Hoplíček presented his paper "Correlation between the Latvian verb prefix -ie and corresponding verb prefixes in Czech" at the 11th International Baltic Student Conference "Bridges in the Baltics" (Vilnius University).
September 26–27, 2024
An international scientific conference "Spoken and written language: synchrony and diachrony" was held at Vilnius University, where Daiga Deksne presented a paper "Adjective word-formation models in Latvian using neo-classical word-parts ULTRA-, MEGA-, HIPER- and SUPER-".
August 21–24, 2024
Ilze Lokmane and Andra Kalnača presented their paper "Compound genitives, noun formation and metonymy in Latvian" at the 57th "Societas Linguistica Europaea" conference (University of Helsinki).
June–July 2024
Participants attend summer schools on different themes.
- On 3-7 June, Guna Rābante-Buša and Viesturs Jūlijs Lasmanis participated in the "Speech Technology Summer School: Charting New Futures" organised by the Rijksuniversiteit Groningen (The Netherlands, Leuvarden; topics: latest speech technology research tools, qualitative data generation, ethical issues) and visited the Fryske Akademy, which is responsible for maintaining and developing the tools of the Frisian language.

- On 8-12 July Agute Klints attended the UniDive Summer School (Moldova, Chișinău), where she learned how to tag multi-word lexemes and learned more about the latest developments in syntactic tagging.

- On 22-26 July, several project members participated in the 6th Baltic Summer School for Digital Humanities (Riga), dedicated to big language models. Normunds Grūzītis, Artūrs Znotiņš and Viesturs Jūlijs Lasmanis led a workshop on automating grammatical text analysis and building multilingual text corpora for quantitative language research:
April 25–26, 2024
Project participants took part in the Baltic DH forum with poster presentations (1) about new speech corpora (LATE-conversations and LATE-media) for facilitating linguistic research and tool development (https://late.ailab.lv); (2) about a versatile platform for digital humanities – Korpuss.lv and (3) about open Latvian and Latgalian speech corpora created from speech data harvested in the campaign “Balsu talka”.
- Korpuss.lv – a versatile platform for digital humanities
- Crowdsourcing Open Speech Corpora in Latvian and Latgalian
- Speech Corpora for Facilitating Linguistic Research and Tool Development

March 14, 2024
The conference "Citizen Science in Latvia", co-organised by LATE, took place at the University of Latvia Library in the framework of the 82nd International Conference of the University of Latvia.
The project was represented by Sanita Reinsone, senior researcher at LU LFMI, and the director of LU LVI.
February 8–9, 2024
Lauma Pretkalniņa (IMCS UL) participated in the UniDive (COST CA21167) meeting and workshops held in Naples, Italy. It was a great opportunity to get to know the members and organizers of Universal Dependencies (UD) and find out what problems researchers face, for example, in transforming the Prague Dependency Treebank (PDT) to UD.
January 31, 2024
The 82nd International Scientific Conference at the University of Latvia continues with the section "Grammar and Language Electronic Resources," co-organized by LATE project participants. LU MII and LU HZF teams participates with presentations.
December 2023
The new collection of articles "Language: Meaning and Form 14. Grammar and Corpus Studies" (Riga: LU Academic Press, 2023) has been published by LU HZF Department of Latvian and Baltic Studies, compiled and edited by Andra Kalnača.

November 23–24, 2023
Guna Rābante-Buša (LU MII) participated in the 28th International Conference "Word and Its Research Aspects" organized by Liepāja University with a presentation titled "Vocalization of 'v' in Consonant Clusters -uv-/-ūv-: A Corpus-Based Study."
September 12, 2023
Representatives from LU MII, Inguna Skadiņa, Ilze Auziņa, and Baiba Saulīte, presented updates on CLARIN-LV, Tēzaurs.lv, and Korpuss.lv at the "Newest Language Resources and Tools for Digital Humanities" CLARIN conference.
August 29–September 1, 2023
LU HZF researchers participated in the 56th Societas Linguistica Europaea Conference in Athens: Andra Kalnača and Ilze Lokmane presented a paper titled "Attitude Dative in Latvian: Speech Acts and Constructions," while Emīlija Mežale discussed "(Im)polite Use of Demonstrative Pronouns in Latvian and Finnish Online Texts."
August 17, 2023
Ilze Auziņa presented at the Latvian Language Agency's conference for distance learning instructors on utilizing achievements in computational linguistics and artificial intelligence in the teaching process.
July 26, 2023
Baiba Saulīte informed participants at the Latvian Language Agency's Letonist Seminar about the practical applications of Latvian language resources.
June 27–29, 2023
LATE researchers participated in the 5th World Congress of Latvian Scientists:
- Andra Kalnača from UL FH discussed Synchronic Linguistic Research in Latvian at LU HZF Department of Latvian and Baltic Studies.
- IMCS and ILFA presented three poster presentations: "Contribution to the Open Latvian Speech Bank with Voice Data," "Korpuss.lv and Tēzaurs.lv for Research and Technology Development," and "Latvian Language in CLARIN Research Infrastructure – A Significant Step Towards Digital Language Equality."
June 26–29, 2023
Lauma Pretkalniņa participated in the "eLex 2023: Electronic Lexicography in the 21st Century" conference in Brno, Czech Republic, presenting Tēzaurs.lv and LU MII publication "Tēzaurs.lv – The Experience of Building a Multifunctional Lexical Resource." The latest research developments in computer lexicography were also discussed, along with a workshop on new and lesser-known possibilities of the Sketch Engine platform.
May 11, 2023
In the LZA (Latvian Academy of Sciences) Humanities and Social Sciences Division session, Ilze Auziņa delivered a lecture on the VPP program "Letonika for the Development of Latvian and European Society" project "Contemporary Latvian Language Research and Language Technology Development" in commemoration of Jānis Endzelīns' 150th birthday.
March 16–17, 2023
The 58th Prof. Arturs Ozols Days International Scientific Conference "Grammar and Word Formation" took place, with LATE researchers from LU HZF and LU MII presenting papers: Daiga Deksne ("Prefixes in Noun Word Formation Models"), Ilze Lokmane ("Clause Subjects in 'Latvian Language Syntactically Annotated Corpus,'" in collaboration with Baiba Saulīte), Paula Kļaviņa ("Demonstrative Pronouns TAS / TĀDS and Expressing Surprise"), Andra Kalnača ("Interjections and Word Formation"), Kristīne Levāne-Petrova ("Transitivity and Passive Constructions"), Ilze Auziņa ("Phonetic Means Typical for Spoken Language: Analysis of Spoken Corpus Data," in collaboration with Guna Rābante-Buša), and Laura Rituma ("Comparison Constructions in 'Latvian Language Syntactically Annotated Corpus,'" in collaboration with Gunta Nešpori-Bērzkalni, Lauma Pretkalniņa, and Baiba Saulīte).
February 23, 2023
Baiba Saulīte and Ilze Lokmane participated in the conference dedicated to Jānis Endzelīns' 150th birthday organized by LU LaVI. In their presentation titled "Infinitive Clause Constructions and Sentence Type Boundaries in the National Corpus Collection," they analyzed the structure and semantics of infinitive clause constructions in various corpora, as well as examined the observed inconsistency in punctuation usage and the rationale behind current punctuation norms in language practice.
09.02.2023
The National Corpus Collection (NCC) has been created, incorporating more than 10 Latvian language corpora developed by various institutions. It is now accessible through the Korpuss.lv platform, which features a unified search system.
24.11.2022
The 27th International Scientific Conference "Word and Its Aspects of Research" was held at Liepaja University, where several presentations were delivered by researchers involved in the LATE project. Daiga Straupeniece and Elza Ozola (LiepU) presented on "The Development Process of the Latvian Sign Language Corpus", Guna Rābante-Buša (LU MII) on "Variations in the Pronunciation of Particles in Different Word Combinations", and Ieva Auziņa (LU LVI) on "The Connection between Some Prefix and Adverb Forms with Non-Derivative and Derivative Verbs".
04.11.2022
Ilze Auziņa and Baiba Saulīte presented a paper on the National Corpus Collection and its potential uses at the conference "Latvian Language in the European Union - Language Technology in Public Administration and Society".
06.10.2022
At the International conference, "Human Language Technologies - Baltic Perspective" (Baltic HLT) held in Riga, Sanita Reinsone (LU LFMI) and Matīss Rikters (University of Tokyo) delivered a presentation on "How Masterly Are People at Playing with Their Vocabulary?". The paper was published in the Scopus-indexed Journal of Modern Baltic Computing.
04.10.2022
The practical seminar "Digital Resources for Linguists" featured a presentation by Baiba Saulīte and Ilze Auziņa (LU MII) on the use of corpora in linguistic research.
20.09.2022
Andra Kalnača and Ilze Lokmane (LU HZF) presented on "Expressive Predicative Constructions in Latvian" at the conference "EXPRESSIVES. Theoretical and Experimental Approaches to the Expressive Content. 9th Experimental Pragmatics Conference 2022" organized by the University of Genoa.
24.08.2022-27.08.2022
At the 55th Annual Meeting of the Societas Linguistica Europaea held at the University of Bucharest in Romania, Andra Kalnača and Ilze Lokmane (LU HZF) presented on "Syntactic Constructions with the Verb Vajadzēt 'to Need, Must' in Latvian".
21.08.2022
Emīlija Mežale (LU HZF) presented on "Article-like Usage of Demonstrative Pronouns: A Case of Finnish and Latvian" at the conference "Congressus XIII Internationalis Fenno-Ugristarum" organized by the University of Vienna.
30.06.2022-02.07.2022
Andra Kalnača, Daiga Degsne, and Tatjana Pakalne (LU HZF) presented on "Latvian Deverbal Nouns in -ien- and -um- and Derivational Productivity: A Corpus-based Analysis" at the conference "Grammar and Corpora" organized by Ghent University.
20.–25.06.2022.
IMCS UL participates in the LREC 2022 conference
LREC 2022 (13th Conference on Language Resources and Evaluation) is taking place in Marseille on June 20-25, 2022. LREC is the major event on Language Resources and Evaluation for Human Language Technologies. The Institute of Mathematics and Computer Science, University of Latvia, participates in the conference with three presentations.
On June 21, there will be a report on the Latvian Language Learner Corpus LaVA, which includes more than 1000 essays written by language learners studying at Latvian universities (corpus size – 190k words). By analyzing the mistakes of the language learners marked in the texts, a set of self-assessment exercise was created.
On June 22, we will present a poster about extending the Tezaurs.lv online dictionary with word sense synonyms and other semantic links, building a new lexico-semantic resource – Latvian WordNet.
Poster presentation on the Latvian National Corpora Collection (LNCC) - a diverse collection of corpora representing both written and spoken language is planned on Midsummer's Day, June 23. All corpora of LNCC are annotated with a uniform morpho-syntactic annotation scheme, enabling federated search and consistent linguistics analysis in more than 20 corpora (1.3B tokens).
16.05.2022–20.05.2022
Emīlija Mežale from LU HZF participated in the summer school "Speech Matters" in Como, Italy. The event focused on various issues related to the study of spoken language, including grammar, emphasis and gesture analysis, peculiarities of different community languages, reference, speech synthesis, and the basics of using the ELAN annotation tool.
12.05.2022
Emīlija Mežale from LU HZF took part in the conference "Subjectivity and Intersubjectivity in Language and Culture", organized by Tartu University and the Estonian Literary Museum. She presented on the topic of "(Im)politeness of colloquial language features in Latvian and Finnish."
30.03.2022
Ilze Lokmane from LU HZF and Madara Stāde from LU MII participated in the section "Language and Culture in the Digital Age" at the 80th International Scientific Conference of the University of Latvia. They presented a lecture titled "Latvian Lexical Network as a Novel Digital Language Processing Tool: Achievements and Prospects."
17.03.2022
Andra Kalnača and Tatjana Pakalne from LU HZF participated in the 6th Nordic and Baltic Digital Humanities Conference (DHNB2022) at Uppsala University in Sweden. They presented on the topic of "Assigning Meaning to Novel Productively Formed Complex Words in Actual Language Use: A Case of the Latvian Agentive Suffix -tāj-."
10.02.2022
The 80th International Scientific Conference of Latvian and General Linguistics was held at the University of Latvia took place. The conference featured a section on "Grammar and Corpus Studies" which was organized by project participants Andra Kalnača and Ilze Lokmane from the HZF LU. Participants from the project: Linda Lauze, Ilze Auziņa, Laura Rituma, Baiba Saulīte, Gunta Nespore-Bērzkalne, Lauma Pretkalniņa, Ilze Auziņa, Kristīne Levāne-Petrova, Roberts Darģis, Ilze Lokmane, Andra Kalnača, Tatjana Pakalne, and Emīlija Mežale. Altogether, the participants from the LATE project delivered eight presentations during the conference.
27.-28.01.2022
Ilze Migla from LU LVI took part in the "Baltic Languages: synchrony and diachrony" section of the international scientific conference "XXXII Scientific Readings." She presented on the topic of "Lexeme putns (bird) in Latvian phraseology."
18.01.2022
LATE kick-off meeting
 On 18 January, the LATE project kick-off meeting took place on Zoom. It was attended by representatives from all partner institutions:
On 18 January, the LATE project kick-off meeting took place on Zoom. It was attended by representatives from all partner institutions:LU MII: Ilze Auziņa, Baiba Saulīte, Normunds Grūzītis, Inguna Skadiņa, Vita Matule
LU LVI: Edmunds Trumpa, Agris Timuška, Sanda Rapa, Marita Silkāne
LU HZF: Andra Kalnača, Ilze Lokmane
LU LFMI: Sanita Reinsone
LiepU: Dina Bethere, Airita Lindberga
12.01.2022
Online hands-on workshop on korpuss.lv platform and searching the corpora, organized by the Institute of Mathematics and Computer Sciences of the University of Latvia in cooperation with CLARIN Latvia. Instructors: Ilze Auziņa and Baiba Saulīte.
https://www.clarin.lv/lv/clarin-latvija-seminari/63-praktiskais-seminars-par-par-korpuss-lv-vietne-pieejamajiem-korpusiem
Information about the project
The project "Research on Modern Latvian Language and Development of Language Technology” is implemented within the framework of the National Research Programme "Letonika – Fostering a Latvian and European Society".
Project No: VPP-LETONIKA-2021/1-0006
Implementation period: 20.12.2021–19.12.2024
Project funding: 1 068 000 EUR
Funded by: Latvian Council of Science of the Ministry of Education and Science
Project partners: Institute of Mathematics and Computer Science of the University of Latvia (leading partner), University of Latvia (Latvian Language Institute of the University of Latvia and Faculty of Humanities of the University of Latvia), Institute of Literature, Folklore and Art of the University of Latvia, Liepāja University
Contacts: [email protected]
Project leader: Ilze Auziņa
Summary
The aim of the project is to advance research on the grammatical, lexical-semantic, phonetic and phonological system of the modern Latvian language, and Latvian sign language using data-driven methods, as well as to develop sustainable Latvian language resources and tools. In order to achieve the goal, the Latvian speech corpus, the pilot corpus of Latvian sign language will be developed, and Tezaurs.lv and “Dictionary of Contemporary Latvian” will be improved. Based on Latvian grammar studies, “Latvian Treebank” will be enhanced. These resources will be integrated into a single Latvian language research infrastructure, as well into the CLARIN-LV repository. During the project, a LATE platform for speech transcription and subtitling will be created.
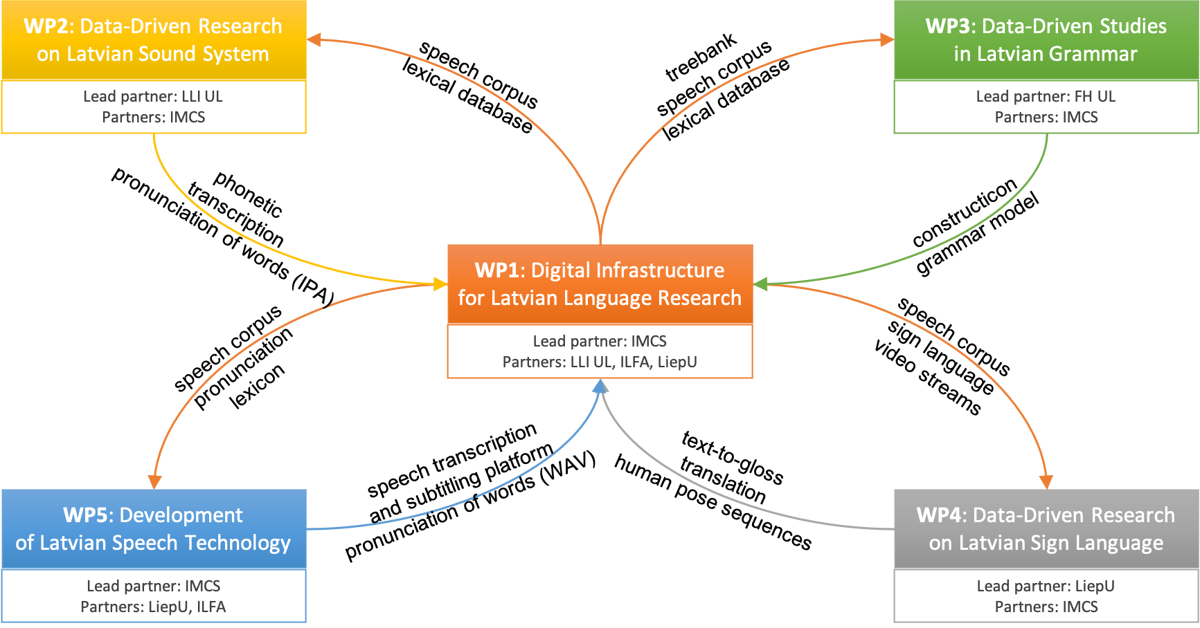
Project's research group: 10 lead participants and 33 participants (including 14 student-participants).



